Introducción
Una lista es la estructura de datos dinámica mas simple. Un array es incluso mas simple, pero no es dinámico. Añadir un solo elemento a un array requiere reasignación de memoria y copiar todo el contenido, de la misma forma que eliminar un elemento. Insertar y eliminar un elemento a una lista es una operación muy rápida y su coste computacional no aumenta a medida que aumentan los elementos. Por esto, las listas sin las estructuras principales usadas en exec.library, el kernel de MorphOS. Se podría decir que Exec está construido sobre listas. Las listas se usan en todo el sistema para controlar procesos, ventanas, pantallas, dispositivos, volúmenes DOS, fuentes, librerías y más. Las listas también se usan por las aplicaciones para manejar datos dinámicamente por supuesto. Muchas estructuras de datos mas sofisticadas están basadas en Listas. Por todas estas razones entender las listas y su uso en MorphOS es esencial para cualquier programador.
Las listas se dividen en intrusivas y no intrusivas. Una lista intrusiva es la que requiere que cada elemento de la lista contenga una parte llamada nodo. El nodo se usa para enlazar elementos a la lista. Una lista no intrusiva crea los nodos ella misma. Ambas tienen sus ventajas. Las listas Exec son intrusivas. ¿Por que? Para una lista no intrusiva añadir un elemento significa asignar memoria para su nodo. Las listas Exec se usan a menudo a un nivel muy bajo del sistema, como el manejo de interrupciones, colas de procesos o dispositivos hardware de entrada/salida. Las llamadas de asignación de memoria serían inaceptables. Y los controles de error serían una pesadilla (cualquier asignación de memoria puede fallar…) En algunas partes las listas del sistema tienen que ser extremadamente rápidas. La asignación de memoria es una operación compleja y no se puede terminar en unos pocos ciclos de procesador. Por supuesto en altos niveles del sistema, las listas intrusivas tienen mas desventajas que ventajas. Por ejemplo un elemento de una lista intrusiva no se puede añadir a mas de una lista. Es por eso que los componentes de mas alto nivel (por ejemplo la clase MUI List) deben ser no intrusiva.
Desde una Lista Sencilla a una Lista de Exec
La forma mas simple de una lista es la unidireccional. El nodo de cada elemento consiste de solo un puntero al siguiente elemento. La lista se identifica manteniendo un puntero al primer elemento. Sin embargo las listas unidireccionales son solo usadas en casos especiales. Mientras que insertar un elemento al comienzo de la lista es sencillo, para insertarlo al final debes recorrer la lista completa. El tiempo de esta operación incrementa linealmente con el número de elementos. Tampoco es posible recorrer la lista hacia atrás. La listas bidireccionales son mucho mas comunes. Las listas de Exec son bidireccionales. Cada nodo contiene dos punteros: uno al siguiente elemento y otro al anterior. Para el primer elemento el puntero que apunta al anterior es NULL. Para el último elemento, el puntero al siguiente elemento es NULL. Si una lista mantiene punteros al primer y último elemento, tiene acceso simétrico al principio y final de la lista.
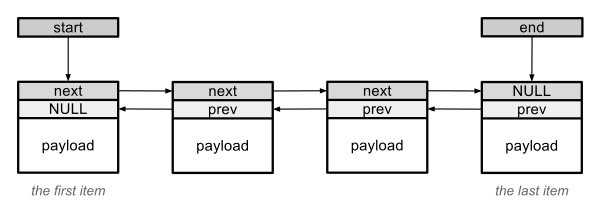
Una lista bidireccional. Un nodo consiste de punteros "prev" y "next".
La idea aún es sencilla, tenemos que complicarlo un poquito. Como hemos mencionado antes, el usuario de una lista mantiene su control usando dos punteros: al primer y al último elemento. Estos punteros se modificarán cada vez que un elemento se añada o elimine al principio o final de la lista respectivamente. ¿Pero que pasa si la lista la usan varios usuarios que no se conocen el uno al otro? Añadir un elemento al principio o al final requeriría actualizar los punteros para todos los usuarios. Para solventar este problema, se introducen dos elementos artificiales: un list head (cabeza de la lista) y un list tail (final de la lista). Estos dos elementos no contienen mas datos, solo consisten de un nodo. Su localización no varía durante la vida de la lista por lo que funcionan como margenes. Al insertar un elemento al principio de la lista en realidad lo hacemos entre la list head y el primer elemento actual. De igual forma pasa al insertar al final que en realidad inserta entre el último elemento actual y la list tail. Como los punteros al principio (list head) y final (list tail) de la lista son constantes, pueden ser usadas por múltiples usuarios.
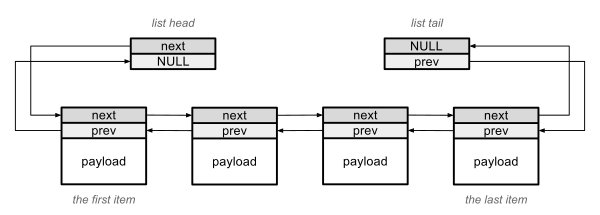
Lista bidireccional con pseudoelementos head y tail.
Las listas de Exec combinan la list head y list tail es una solaestructura llamada list header. Como el Exec fue diseñado en los días en los que la memoria de los ordenadores se contaban en kilobytes en vez de en gigabytes, los diseñadores vieron una forma de ahorrar unos poco bytes. El puntero "previous" del nodo list head siempre contiene NULL. Igualmente el puntero "next" de list tail siempre contiene NULL. Entonces ambos se pueden unir en uno. Es por eso que la list header solo contiene tres punteros en vez de cuatro. En lenguaje C la list header se define como struct List y las listas son referenciadas como un puntero a ella.
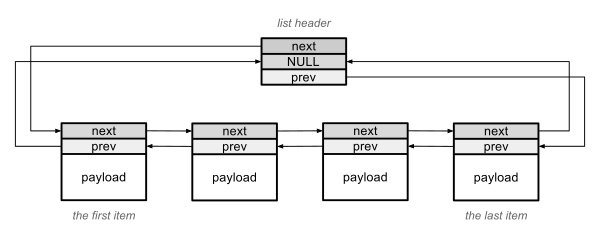
La lista de Exec. Head y Tail pseudoelementos están unidos en list header.
Elementos de la lista de Exec: Nodo y Header
Exec define dos tipos de nodos: Uno completo y uno mínimo. El mínimo consiste solo de punteros a los elementos anterior y siguiente y es definido en C en el fichero de cabecera <exec/modes.h> de la siguiente forma:
struct MinNode
{
struct MinNode *mln_Succ; // successor, the next item
struct MinNode *mln_Pred; // predecessor, the previous item
};
El nodo completo tiene campos adicionales que se usan en muchas listas del sistema. Estos campos son: elementos name, type y priority.
{
struct Node* ln_Succ; // successor
struct Node* ln_Pred; // predecessor
UBYTE ln_Type; // item type
BYTE ln_Pri; // item priority
char* ln_Name; // item name
};
Los campos adicionales del nodo solo tienen importancia para las listas del sistema y se pueden considerar parte de los datos. Si ignoramos los tipos de C, un Node es simplemente un MinNode con tres campos añadidos al final. El campo de prioridad de nodo puede ser usado para implementar listas ordenadas o colas. Exec.library tiene funciones para insertar elementos.
Como hay dos tipos de nodos, también hay dos tipos de list headers. Ambas están definidas en <exec/lists.h>:
struct MinList
{
struct MinNode* mlh_Head; // pointer to the first real item
struct MinNode* mlh_Tail; // merged head "previous" and tail "next"
struct MinNode* mlh_TailPred; // pointer to the last real item
};
El Header para los nodos completos tiene un campo adicional type (usado por las listas del sistema) y un byte pad para que el tamaño de la estructura sea par.
struct List
{
struct Node* lh_Head; // pointer to the first real item
struct Node* lh_Tail; // merged head "previous" and tail "next"
struct Node* lh_TailPred; // pointer to the last real item
UBYTE lh_Type;
UBYTE lh_pad;
};
De nuevo, cuando ignoramos los tipos de C, la estructura List es MinList con dos campos extra.
Como las listas de Exec son intrusivas, cuando creamos una estructura para una lista debemos incluir MinNode (o Node si es necesario) como el primer campo de la estructura. Debe de ser una estructura completa, no un puntero. Veamos un ejemplo:
struct MyNode
{
struct MinNode Node; // must be the first
struct Whatever Foobar; // example payload fields
ULONG Something;
char MoreData[10];
/* … */
};
No hay limite de tamaño para la estructura que creamos. Como los elementos no se copian, los elementos muy grandes se manipulan a la misma velocidad que los pequeños.
Inicializar la Lista, Comprobación de Listas Vacías
La list header, que puede ser una estructura List o MinList debe ser inicializada antes de usarse. Esto es importante:
Limpiar la List con todo ceros no es una manera correcta de inicialización de listas Exec.
Mirando el siguiente diagrama, sabemos como es una lista vacía.
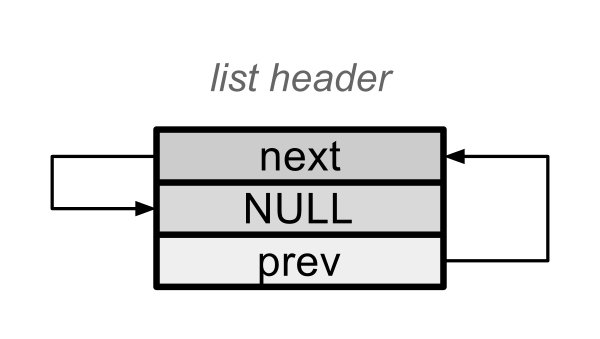
Una lista vacía
Una lista vacía solo contiene su comienzo y final, ambos unidos en el header. Si recordamos un poco lo anterior, la inicialización parece obvia:
- El campo "next" de head apunta al final (tail).
- El campo "prev" de head es NULL.
- El campo "next" del final (tail) es NULL.
- El campo "prev" del final (tail) apunta a head.
Entonces la segunda y tercera operación se fusiona en una sola, pues los campos están fusionados. El siguiente código ejecuta una correcta inicialización de una lista de Exec. Fíjate en el operador de dirección &, olvidarlo es un típico error:
struct MinList mylist;
mylist.mlh_Head = (struct MinNode*)&mylist.mlh_Tail;
mylist.mlh_Tail = NULL;
mylist.mlh_TailPred = (struct MinNode*)&mylist.mlh_Head;
En el caso de una List completa, la inicialización es igual, solo hay que hacer un typecast de Node en vez de MinNode. La inicialización de una lista es una operación muy común, por lo que <exec/lists.h> define el macro NEWLIST para esa operación. El macro coge un puntero a Lisu o MinList, por lo que el ejemplo anterior se resume de la siguiente manera:
NEWLIST(&mylist);
Comprobar si una lista esta vacía también es otra operación muy común. Deriva del siguiente diagrama.Se puede comprobar si una lista está vacía usando cuatro condiciones de equivalencia:
if (mylist.mlh_Head->mln_Succ == NULL) /* list is empty */
if (mylist.mlh_Head == (struct MinNode*)&mylist.mlh_Tail) /* list is empty */
if (mylist.mlh_TailPred->mln_Pred == NULL) /* list is empty */
if (mylist.mlh_TailPred == (struct MinNode*)&mylist.mlh_Head) /* list is empty */
En <exec/lists.h> se define un macro IsListEmpty() que usa la última condición, simplificado por el echo de que la dirección de mlh_Head es la misma dirección que MinList (un buen compilador optimizará el campo de referencia de todas formas).
Iterando una Lista
Una iteración de una lista es un fragmento de código (normalmante un bucle) que recorre la lista y ejecuta operaciones en sus elementos. La iteración mas simple generalmente es implementada con un bucle for:
struct MyNode *n;
struct MinList *list; // let's assume it is initialized alreadyfor (n = (struct MyNode*)list>mlh_Head; n>Node.mln_Succ; n = (struct MyNode*)n>Node.mln_Succ)
{
/* do something with node 'n' */
}
La primera parte de la declaración for inicia un puntero n al primer elemento real de la lista (el siguiente del elemento head). La segunda parte es la condición final del bucle. El bucle acaba cuando el siguiente elemento es NULL, que ocurre cuando el elemento actual es el último. En ese caso el contenido del bucle no se ejecuta puesto que tail (último pseudoelemento) no es un elemento "real", como hemos dicho anteriormente. Por último, la tercera parte del bucle for hace que el puntero apunte al siguiente elemento de la lista. Se puede escribir un iterador simétrico para recorrer la lista desde el final hasta el principio:
for (n = (struct MyNode*)list->mlh_TailPred; n->Node.mln_Pred; n = (struct MyNode*)n->Node.mln_Pred)
{
/* do something with node 'n' */
}
Esta vez el puntero n apunta al último elemento real (predecesor de list tail), el puntero se mueve al elemento anterior en cada turno del bucle. El bucle acaba cuando el predecesor del elemento actual apunta a NULL, que ocurre cuando apunta a list head. De nuevo, el bucle no se ejecuta en ese caso.
La cabecera <exec/lists.h> proporciona el macro ForeachNode() para construir una iteración basada en el bucle for. Sin embargo este macro es un poco peligroso, porque oculta un typecast del puntero nodo a struct Node* y el puntero a la lista struct List*. Efectivamente evita el tipo de control estático del lenguaje C y puede llevar a errores en el código. Es mas seguro hacer typecasting al puntero del nodo con el tipo real del elemento de la lista, Como hemos hecho en los ejemplos anteriores. Un macro mas seguro cogería el nombre del tipo de elemento como uno de sus argumentos:
#define ForEachNode(n, T, list) for (n = (T)(list)->mlh_Head; n->Node.mln_Succ;
n = (T)n->Node.mln_Succ)
El macro se usaría de la siguiente manera:
ForEachNode(n, struct MyNode*, list)
{
/* do something with node 'n' */
}
Este macro no es universal, pues asume una lista MinList y que el campo MinNode está puesto al comienzo de la estructura MyNode se llama Node. Por otro lado hace buen uso del control de tipos haciendo typecasting. Se puede definir un macro similar para hacer iteraiones hacia atrás. En el lenguaje C++ las iteraciones de las listas Exec se pueden definir como plantillas.
Eliminar un elemento de la Lista desde un iterador
Hay que poner atención en el caso de usar iteraciones para la eliminación selectiva de elementos. Se podría usar lo siguiente:
/* BAD CODE EXAMPLE */
ForEachNode(n, MyNode, list)
{
if (/*some condition*/)
{
Remove((struct Node*)n);
FreeVec(n);
}
}
¿Por que este código está mal? Si el elemento n se elimina y su memoria es eliminada, la referencia a n en el siguiente ciclo del bucle será una referencia a un bloque de memoria libre. En la mayoría de los casos el contenido de la memoria permanecerá sin cambios. Por eso este error es tan popular, es posible que no lo notes si el código no se comprueba lo suficiente. Nada detiene el planificador de procesos pueda cambiar nuestro proceso, y entonces la memoria puede ser requerida por otro proceso y su contenido sobreescrito. Entonces, cuando el control vuelve a nuestro proceso, n apunta a datos no definidos y el bucle falla. Una solución a este problema es leer el elemento posterior de un elemento antes de que el elemento sea eliminado. Se necesita definir un segundo puntero:
struct MyNode *n, *n2;
for (n = (struct MyNode*)list->mlh_Head; n2 = (struct MyNode*)n->Node.mln_Succ; n = n2)
{
if (/* some condition */)
{
Remove((struct Node*)n);
FreeVec(n);
}
}
Ahora un puntero al elemento posterior del elemento n es almacenado en n2 antes de que el elemento n es liberado. En el siguiente ciclo del bucle, el iterador se mueve al siguiente elemento y comprueba sin es el final de la lista usando un puntero n2 válido en vez de una referencia a un bloque de memoria vacía.
Las cosas son mas sencillas si vamos a eliminar todos los elementos incondicionalmente, con lo que la lista queda vacía y todos sus elementos son eliminados. Por supuesto que aún podemos usar el bucle seguro visto antes, pero hay alternativas un poco mas rápidas:
while (n = (struct MyNode*)RemHead((struct List*)list)) FreeVec(n);
También se puede usar RemTail() en este bucle, porque cuando eliminamos todos los elementos, generalmente el orden no importa.
Añadir y Eliminar Elementos
Añadir un elemento en una posición arbitraria requiere solo actualizar 4 punteros, sin importar el tamaño del elemento. El siguiente diagrama explica la operación.
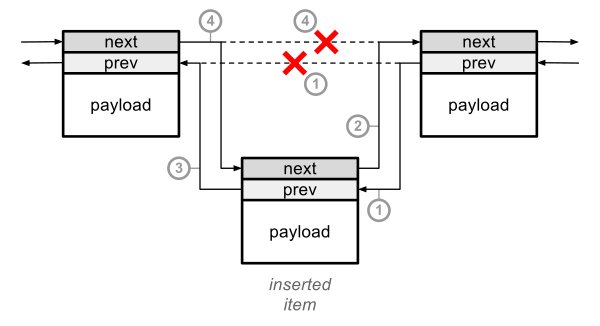
Insertando un elemento en una lista Exec.
El diagrama corresponde al siguiente código:
struct MyNode *n; /* insert after this item */
struct MyNode *a; /* insert this */n->Node.mln_Succ->mln_Pred = &a.Node; /* 1 */
a->Node.mln_Succ = n->Node.mln_Succ; /* 2 */
a->Node.mln_Pred = &n.Node; /* 3 */
n->Node.mln_Succ = &a.Node; /* 4 */
Observa el orden de las operaciones. Es importante. Si empezamos desde la operación 4 por ejemplo, perderemos el único enlace al resto de la lista después de la posición de inserción.
Eliminar el enlace es incluso mas rápido, pues solo requiere modificar dos punteros: uno en el predecesor del elemento eliminado y otro en el siguiente. Vamos a asumir que eliminamos el elemento n:
n->Node.mln_Pred->mln_Succ = n->Node.mln_Succ;
n->Node.mln_Succ->mln_Pred = n->Node.mln_Pred;
Las operaciones de insertar y eliminar han sido estandarizadas en MorphOS de dos maneras: como llamadas al API en exec.library o como macros. Las funciones son Insert() y Remove(), las macros se llaman INSERT() y REMOVE(). Tanto la función Insert() como la macro INSERT() usan un puntero al inicio de la lista. Aunque no es necesario en general, permite insertar un elemento en la primera posición pasando NULL como posición de inserción. Tambien se puede insertar en la primera posición pasando la dirección del header de la lista como posición de inserción.
Date cuenta que tanto la función Remove() como el macro REMOVE() no verifica si el nodo es realmente eliminado en cualquier lista. Cualquier intento de "eliminar" un nodo que no esta en la lista puede producir en memoria corrupta, bloqueos y reseteos.
Head y Tail
Las operaciones mas comunes de inserción y eliminación de elementos se ejecutan en los dos finales de la lista. Por ejemplo, las estructuras de datos comunes como la pila o las listas pueden implementarse usando list. Para la pila, los elementos se agregan en el comienzo de la lista y también se eliminan del comienzo. Para las listas, los elementos se agregan al principio de esta y se eliminan al final.
Tener pseudoelementos de inicio y final de lista ofrece la ventaja de que las operaciones en ambos extremos de la lista no son diferentes del caso general. Simplemente se reemplaza, en el diagrama del subcapítulo anterior, el elemento antes de la posición de inserción con el principio de la lista, o el elemento después de la posición de inserción con el final de la lista. La única diferencia es el hecho de que las operaciones de Hail y Tail generalmente toman solo la dirección del encabezado de la lista como argumento (por supuesto, las operaciones de inserción también toman una dirección del nodo insertado). Se proporciona el conjunto completo de cuatro operaciones:
- La función AddHead() y la macro ADDHEAD() añaden un nodo como el primero de la lista.
- La función RemHead() y la macro REMHEAD() eliminan el primer nodo de la lista y devuelve su dirección.
- La función AddTail() y la macro ADDTAIL() añaden un nodo al final de la lista.
- La función RemTail() y la macro REMTAIL() eliminan una macro del final de la lista y devuelven su dirección.
Las operaciones de eliminar devuelven la dirección del nodo eliminado, o NULL si la lista esta vacía.
¿FUNCIONES O MACROS?
Después de leer todo lo anterior, queda claro que la mayoría de las operaciones de la lista son muy simples y se compilan en unas pocas instrucciones. Por eso también se definen como macros. ¿Qué usar entonces? En general, las macros son más rápidas, pero algunas de ellas pueden ser unos bytes más largas que las llamadas a funciones de las librerías (especialmente INSERT ()). Por otro lado, incluso unos pocos kilobytes de código adicional no suelen ser un problema hoy en día, mientras que la ganancia de velocidad suele ser valiosa. Luego, en lugares donde la velocidad es fundamental, las macros son una mejor opción.
Enqueueing
Los nodos de la lista completa tienen un campo de prioridad, llamado ln_Pri. El sistema suele utilizar el campo para mantener listas priorizadas. Para tener la lista ordenada por prioridad, se requiere una operación de inserción especial. exec.library tiene una función llamada Enqueue (). La función toma un nodo (debe ser Nodo completo, no MinNode), lee su prioridad y encuentra un lugar para insertar comparando las prioridades de los nodos. Si hay algún nodo en la lista con la misma prioridad que el insertado, se inserta antes que los ya existentes. Por supuesto, Enqueue () también se puede utilizar para implementar listas personalizadas. Sin embargo, hay que tener en cuenta que el campo de prioridad está limitado a un número de 8 bits con signo y la función no función bien para listas muy largas, ya que la búsqueda de la posición de inserción es lineal.



